Preface
In Part 2 we further explored the Azure Integration Services considerations and represented a complete design. In Part 3 we will include Disaster Recovery, redundancy and high availability considerations.
The Next sections will also present a way to handle provisioning and maintenance of the various resources.
High Availability and Redundancy
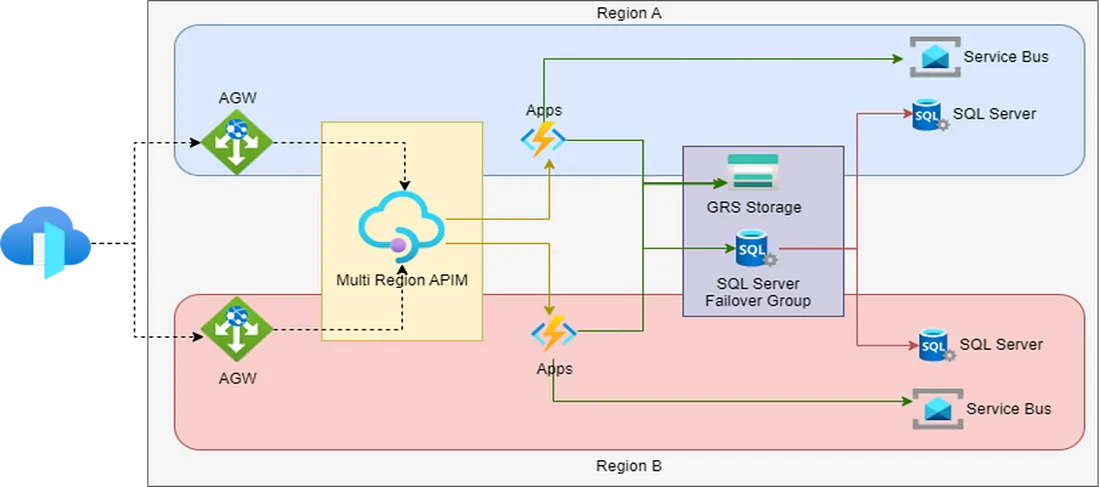
API Availability
High availability for API’s in APIM can be achieved using a combination of APIM features.
A single APIM can be configured to leverage multiple regions ( https://learn.microsoft.com/en-us/azure/api-management/api-management-howto-deploy-multi-region ). This enables us to leverage single APIM for multiple regions.
Along with Multi Region APIM we can configure API policies which route api calls to respective regions leveraging policy similar to mentioned here: route-api-calls-to-regional-backend-services
We can add backend api redundancy with policy similar to redundancy.policy.xml and Template.xml. These policies will retry a backend app/API for some interval and redirect to secondary if primary region is unable.
We can also use capacity to cache regional backend information and redirect traffic temporarily to secondary region based on APIM cache values.
Leveraging all these capabilities we can enable High Availability and redundancy for API’s in APIM.
App Availability and Redundancy
For HTTP triggered Logic/Function Apps we need to create and deploy application in both regions.
Leverage the APIM policy discussed in above section api calls can be directed to respective apps.
Consider availability of private endpoints for regional traffic.
App service plan zone redundancy for Logic/Function Apps helps with availability zone redundancy.
Storage Accounts Availability
Data/Feed Storage Accounts should be Geo Redundant (GRS or GZRS) to support regional failures.
Once failover is initiated storage account might take ~15 min (depending on volume of data) to fully replicate to a new region.
There is a chance of minimal data loss with storage account failover.
Function/ Logic App storage should be ZRS to support zone redundancy for app service plans.
Failover needs to be initiated manually
SQL Server Availability
SQL server supports failover groups that helps with failover of SQL servers in multiple regions.
Failover group provides alias for connectivity to SQL databases in both region.
Databases are replicated across multiple regions.
It is recommended to use Customer Managed failover instead of Microsoft managed Failover (failover-policy)
Service Bus Availability
Service bus also support Geo-Disaster recovery but this feature has some challenges as mentioned here :
Geo Disaster recovery only replicates the schema while there is no data replication.
The secondary service bus needs to be empty for it to be attached to the Alias.
Once failover is initiated the primary server becomes detached from the alias and the secondary server becomes standalone. This means all the queues, subscription, topics etc. need to be deleted for the service bus to be re-added to the alias.
Hence its is better to create separate servers for each region and customize application logic to support multi region service bus. Do consider sequencing challenges with this approach.
Note: There is a preview feature for service bus data replication as mentioned here